
这是一个创建于 3235 天前的主题,其中的信息可能已经有所发展或是发生改变。
大数据平台基础建设当前的趋势是云化与开放,这个平台需要可以提供各类大数据相关 PaaS 服务,也需要使各类服务间可以简单灵活的组合来满足多变及定制的需求。如何在云上提供弹性、敏捷,却不失稳定和高性能的大数据平台?如何高效的利用云计算的特点来开发大数据平台?
本期中国互联网技术联盟分享活动中青云 QingCloud 系统工程师周小四给大家带来基于云计算的大数据平台基础设施建设以及其架构特点的主题分享。
以下是分享原文。
——————
大家晚上好,我是周小四,英文名字 Ray ,江湖尊称“四爷",现在负责青云 QingCloud 大数据平台的开发。今天跟大家分享一下在云上建设大数据基础平台的问题,下面我提到的大数据是特指大数据基础平台,比如 Hadoop 、 Spark 等,而不是指上层应用。
我会从四个方面和大家交流一下:云计算与大数据,云上大数据平台建设的挑战,大数据基础平台,数据格式。
一、云计算与大数据
相信大家平时接触更多的是物理机方案的大数据,本来这个话题我并不想总讲,因为在我们看来大数据的发展方向是云化和开源,是一个顺理成章的事情,但是在实际实施中会遇到一些阻力,这是因为我们有相当一部分人还是物理机世界做大数据的思维,还有对云计算的不信任,稍微有风吹草动就怀疑云计算,这显然是不对的。怀疑大数据云化无外乎就是稳定性和性能,不过好消息是越来越多的人已经意识到也认可这个发展方向,相信以后这就不再是个话题了。
我们还是从大数据本身出发。我们在准备做一个大数据项目的时候,首先是确定需求,然后就是平台的选型,平台的选型是一个最难、最重要的、也是大家最困惑的环节,我遇到的客户基本上都在这个问题上有不同程度的纠结,这个完全可以理解,因为东西太多了,并且还有更多的新东西源源地不断地出来。
其实平台的选型完全取决于你的需求,你是实时计算还是离线计算,是处理结构化数据还是非结构化数据,你的应用有没有事务性要求等等。确定这些需求后就找相应的平台就行了,这就要求我们对每个平台的特点要了解。我们知道没有一个平台能解决所有的问题, Spark 再强大也没有存储,很多场景需要和 Hadoop / HBase / 对象存储等配合起来使用,更别说替换数据仓库了。
选择平台或工具不能赶时髦,适用才是最正确的,有些东西并一定就只有 Hadoop 或 Spark 才能解决,比如 redis 提供了一个很好的数据结构 hyperloglogs 用来统计独立事件,而内存最多只会用到 12k 字节,跟多少个独立事件无关,误差不超过 1 % ,那么用这个来统计每个时段的独立事情比如 UV 还是很不错的选择。
每个平台有自己特定的使用场景,我们不但要了解它,甚至很多时候我们还会对各个候选平台做个 POC 或 benchmark 测试,这个时候云计算就体现出优势了,你可以快速地、低成本地做试验。
当然云计算的优势不仅仅这些,大数据时代有很多不确定性的东西,能够说出半年之后你的数据量一定会增加到多少的人不会太多,云计算的弹性能很好地解决这个问题,需要多少就增加多少资源,还能释放过剩资源给其它业务使用,上下左右任意地伸缩,这些都可以通过鼠标点击几分钟完成。你甚至可以通过调用 API 的方式来操控这些平台,比如说我的程序里接收到数据,我启动我的 Spark 集群来处理这些数据,处理完之后我可以关闭集群;也可以通过定时器或自动伸缩功能去完成这些事情,从而极大的节约成本。
云计算不仅仅有弹性、敏捷性,还非常灵活,你可以任意搭配一些组件组成不同的解决方案。比如我们现在要做的一件事情就是基于数据任意切换计算引擎,因为我们知道大数据是计算跟着数据走,数据在那儿,计算跑到那儿,那么有的用户对 MapReduce 比较熟悉,他可能就是用的 Hadoop ,但过段时间他想用 Spark 了,这个时候不能让用户去拷贝数据到 Spark 集群,而应该是换掉上面的 MapReduce 变成 Spark ,数据还是原来的 HDFS 。所有的这些都能帮我们把时间和精力放在业务层面,而不是去倒腾复杂的大数据平台。
二、云上大数据平台建设的挑战
可以看出云上的大数据能给我们带来无与伦比的体验,但是云上大数据最关键的并不是这些东西,而是稳定性和性能,这也是怀疑大数据云化最主要的两点。而这两点所依赖的是 IaaS 的能力,考验你的是虚拟化的技术好不好,不能压力一上来就 kenel panic ,不过我们是从来没遇到过这个问题,所以我就不多说这个。
性能这个问题确实需要花大力气说,性能分磁盘 I/O 性能和网络性能,磁盘性能如果从相同配置的单节点来说,虚机确实没有物理机性能好,这是因为虚拟化总是有损耗的,但是,如果你虚拟化技术足够好,损耗可以降到很低,同时云计算是靠横向扩展解决复杂问题的,而不是靠纵向扩展,一个节点不行我多加一个节点。并且我们现在想到了更好的办法解决这个问题,让磁盘性能得到更大的提升。
网络性能在物理世界也存在,尤其是节点一多,如果一不小心网络配置不够好,性能一样会差。我们最近刚发布的 SDN 2.0 就帮我们的大数据解决了这个大问题,所有的主机之间网络通讯都是直连,跟节点多少没有关系,并且节点间带宽能达到 8 Gb ,已经接近物理网卡单口的上限了。况且现在 25 Gb 的网卡成本也越来越接近 10 Gb 的网卡,所以网络不应该是问题,当然前提是你的 SDN 技术足够牛。
关于磁盘 I/O 的问题我再补充一点,我们知道 HDFS 默认的副本因子是 3 ,但是在云上就会变得不一样,你如果在一家云服务商上自己部署 Hadoop ,就不应该设定 3 个副本因子。这是因为 Hadoop 设计第三个副本的初衷是防止整个机架出问题而把第三个副本放在另外一个机架上,你在别人家部署的时候你肯定不知道这个信息的,所以第三个副本是没有意义的,同时任何一家 IaaS 服务商一定会提供资源层面的副本的,数据的安全性能得到保障,所以更应该去掉第三个副本,去掉这个副本可以节省 1/3 的空间,性能还能得到提升。
但是,不能因为 IaaS 有副本就把 HDFS 降低到一个副本,原因是你需要业务层面的 HA , IaaS 的副本只能保证数据不丢,物理机出故障切换需要几分钟的时间,如果 HDFS 只有一个副本的话这个切换过程业务会受影响,所以 2 个副本还是必须的。即便这样其实还不是最优的方案,因为业务层 2 个副本加上 IaaS 层至少 2 个副本,加起来就至少 4 个副本了,比物理机方案的 3 个副本还是有差距。所以最好就是去掉底层的副本,在云上实现物理机世界的 3 个副本方案,然后加上 Rack awareness ,这个就跟物理机部署一样了,但是是以云的方式交付给大家。这个工作 IaaS 提供商是可以做的,因为这些信息是可以拿到的。
三、大数据基础平台

接下来我们看看有哪些大数据平台以及它们的特点,从数据的生命周期来说分采集,传输,存储,分析计算以及展现几个阶段,上面这张图描述了这几个阶段现在比较流行的工具和平台。
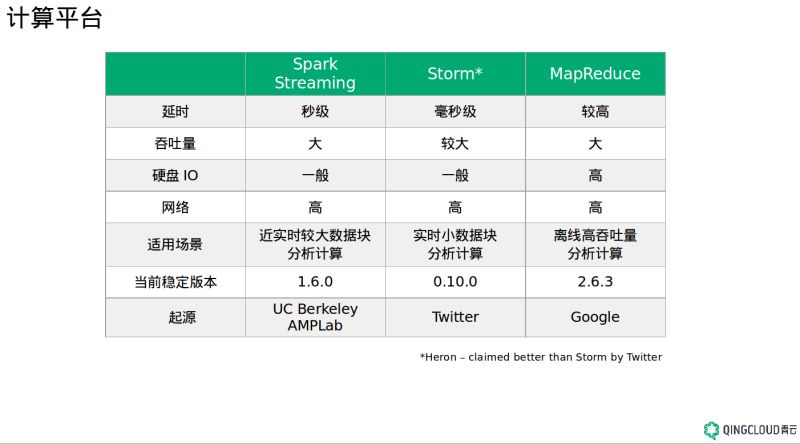
首先讲讲计算,如 Spark 、 Storm 、 MapReduce 等,他们的区别主要在实时计算和离线计算,进而影响着各自的吞吐量。 MapReduce 是老牌的大数据计算引擎,每个 Map 、 Reduce 阶段通过硬盘来进行数据的交互,对硬盘 I/O 要求比较高,速度也慢,所以适合离线计算,这就导致凡是跟 MapReduce 相关的东西都比较慢,比如 Hive 。
Storm 实时性比较高,但吞吐量相对来说比较小,所以它适合实时小数据块分析计算场景。 Twitter 号称 Heron 比 Storm 延迟更低,吞吐量更高,去年年底会开源,但我好像至今并没有看到更多的新闻,耐心期待吧。
Spark Streaming 更适合近实时较大数据块分析计算, Spark 是一个基于内存的分布式计算系统,官方上声称它比 Hadoop 的 MapReduce 要快 100 倍,其实 Spark 的核心是 RDD 计算模型以及基于全局最优的 DAG 有向无环图的编排方式,而 MapReduce 是一种着眼于局部的计算模型,直接导致了 Spark 即使基于硬盘也要比 MapReduce 快 10 倍。 Spark 是一个很值得研究的平台,相信大家都知道它有多么优秀。
对于 SQL 分析来说现在主要分两大流派,基于 MPP 的数据仓库和 SQL-on-Hadoop 。
现在看起来后者占了点上风,主要的原因之一是前者需要特定的硬件支持,不过 MPP 的数据仓库在传统行业还有很大市场,也很受传统行业的欢迎,因为它有 Hadoop 目前还没有的东西,比如真正意义上支持标准的 SQL ,支持分布式事物等,使得 MPP 数据仓库能很好的集成传统行业现有的 BI 工具。另外, MPP 数据仓库也在向 Hadoop 靠拢,支持普通的 X86 服务器,底层支持 Hadoop 的存储,比如 Apache HAWQ 。青云 3 月底的样子会提供 MPP 数据仓库服务,是由 HAWQ 的作者兼 GreenPlum 的研发人员和我们合作开发这个服务。 SQL-on-Hadoop 就比较多了,比如 Spark SQL 、 Hive 、 Phoenix 、 Kylin 等等, Hive 是把 SQL 转换为 MapReduce 任务,所以速度比较慢,如果对运行速度有要求,可以尝试 Spark SQL ,学起来也很简单, Spark SQL 1.6.0 的性能有很大提升,大家感兴趣可以体验一下。
还有基于 Hadoop 的 MPP 分析引擎 Impala 、 Presto 等等,我就不一一介绍了。需要注意的是有些项目还在 Apache 的孵化器里,如果想在生产环境中使用需加小心。这个地方有意思的是大家都跟 Hive 比,结论都是比 Hive 快多少倍,这个是肯定的,我们更想看到的这些新出来的 SQL 相互间比是怎么样的,别总拿 Hive 比,也许是小兄弟好欺负。
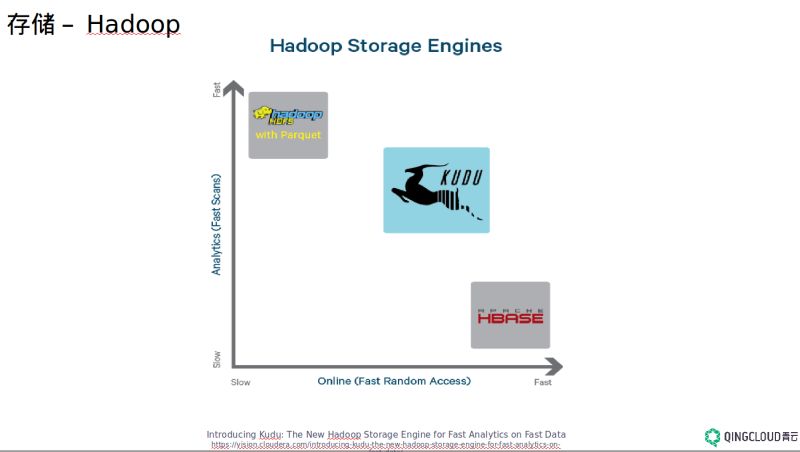
存储主要就是 Hadoop/HDFS 、 HBase 、对象存储以及 MPP 数据仓库。 Hadoop 是适合大文件一次性写入、多次读取的场景,不能写很多小文件, NameNode 很容易垮掉,如果非要写小文件的话可以网上搜一些小技巧。 HBase 适合随机读写场景,它是一个 NoSQL 的分布式列式数据库,是一个 sparse 、 distributed 、 persistent 、 multidimensional sorted map ,把每个单词理解透了就可以理解 HBase 是一个什么东西,它的底层用的还是 HDFS ,不过在分析场景如 scan 数据的时候它的性能是比不上 Hadoop 的,性能差 8 倍还要多。 HBase 强在随机读写, Hadoop 强在分析,现在 Apache 孵化器里有一个叫 Kudu 的“中庸”项目,就是兼顾随机读写和分析性能。 HBase 想强调的一点的是数据模型的设计,除了我们大家都知道的 rowkey 设计的重要性之外,不要用传统的关系型数据库思维建模,在大数据领域里更多的是尽量 denormalize 。
传输现在主流就是 Kafka 和 Flume ,后者有加密功能, Kafka 需要在业务层做加密,如果有需求的话。 Kafka 是一个分布式、可分区、多副本的高吞吐量低延迟消息系统,对于活跃的流式数据处理比如日志分析是最好不过的选择。

上图是我从一个真实客户的 kafka 实时监控图截取过来的,能看出流入流出的两个曲线完全重叠了,我们能看出它的延迟非常低(毫秒级别)。
但是我们不能滥用 Kafka ,我曾经遇到过有人想用 Kafka 做分布式事务性的业务如交易,但 Kafka 并没有宣称它支持消息的传递是 exact once ,它能做到是 at least once ,所以分布式事务性的业务应该是不适合的,需要业务层做一些工作。
四、 数据格式
最后一个我想强调的是数据格式,数据格式的正确选择对大数据怎么强调都不为过。选择错了会极大的浪费存储空间,大数据本来数据量就大,经不起成倍空间的浪费,性能也会因为格式选择错误急剧下降,甚至都无法进行。
数据格式要记住两点,可分割和可块压缩。可分割的意思就是一个大文件从中间切割,分析器还能不能单独解析这两个文件,比如 XML ,它有 open tag 和 close tag ,如果中间来一刀, XML Parser 就不会认识。但 CSV 就不一样,它是一个个的记录,每一行单独拿出来还是有意义的。
可块压缩指的是每个分割出来的块能否独自解压缩,这是因为前面说过的大数据是计算跟着数据走,所以每个节点的计算是分析本地的数据,从而做到并行计算。但有些压缩格式如 gzip , CSV 在解压的时候需要从第一分割块开始才能解压成功,这样就做不到真正的并行计算。
五、 总结
最后总结前面讲的几个观点:大数据的发展方向是云化,云计算才是大数据基础平台最好的部署方案;大数据解决方案中应该根据你的需求来选择平台;数据格式的选择很重要,通常情况记住要选择可分割和可块压缩的数据格式。
更多内容community.qingcloud.com
第 1 条附言 · 2016-01-20 11:20:36 +08:00
哎,你们这些人只收藏,不回复是啥意思来着。哼
 |
1
jonechenug 2016-01-19 23:58:35 +08:00 via Android
太长了
|
 |
2
chousb OP @jonechenug 好东西就得长
|
 |
3
wh0syourda66y 2016-01-20 14:04:43 +08:00
作者对大数据生态圈的技术都很熟啊
|
 |
4
domino 2016-01-20 15:33:08 +08:00 via Android
留著以後看
|
 |
5
Kusanagi 2016-01-21 11:02:16 +08:00 via Android
先收再看
|
|
6
chousb OP @wh0syourda66y 就是做这个的哇。
|
