
这是一个创建于 650 天前的主题,其中的信息可能已经有所发展或是发生改变。
大家好,我是马称。
最近,有很多同学在微信上问我这么一个问题:
Hippo4j 动态线程池框架是美团开源的么?
类似于这样的问题还挺多,在这里统一回复下:
美团官方并没有开源任何关于动态线程池的框架。
美团官方关于对动态线程池框架的唯一产出,来自于大家基本上看过或者有印象的一篇博客。
如果不了解动态线程池概念的同学可以深入了解下。文章深入浅出,讲的很透彻,同时也是美团罪受欢迎的文章之一。
在此之后,美团官方并没有基于动态线程池这个 IDEA 做任何的产出。不过,开源社区基于美团这篇文章做了很多开源框架,比如笔者开源的 Hippo4j ,以及另外一位开源作者 DynamicTP 框架等。
说完 Hippo4j 是否美团动态线程池开源后,接下来和大家聊两件和平常工作有关并且有意思的事。
美团动态线程池框架为什么没有开源
根据我的想法,如果当初美团推出动态线程池概念后,顺势推出一款开源框架,肯定会“爆火”。
毕竟,对于工作这么多年的开发来说,谁的线上环境还没有被线程池“坑”过呢。
但是,实际却没有按照这种设想发展,我就找了在美团工作的朋友聊了聊,下面根据我的了解说下是怎么回事。
1. 依赖办公软件大象
动态参数通知和线程池运行中报警,都需要通过办公通信软件或者邮件进行通知。
通过上面提到的美团动态线程池文章可知,在线程池变更通知和过载告警功能上,依赖了美团办公通信软件大象。
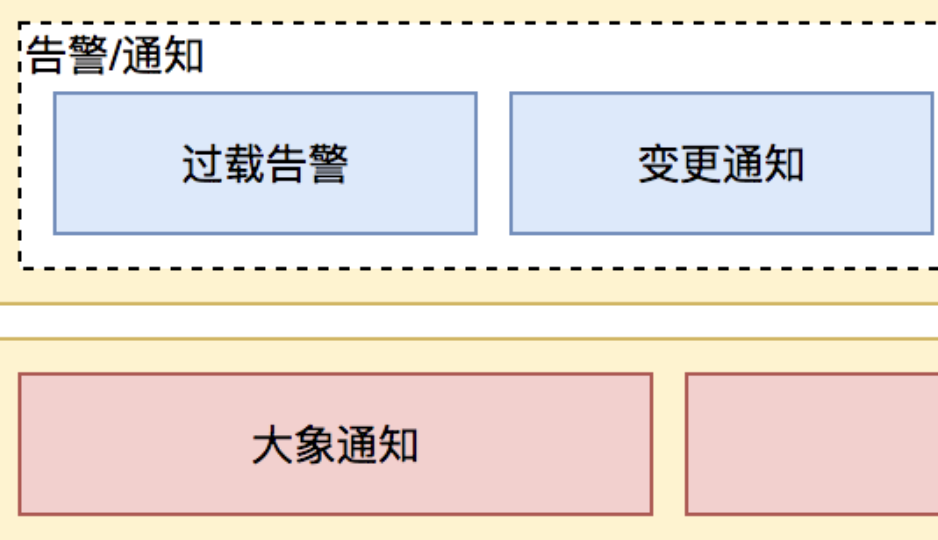
如果要开源,如何进行改造呢?
基于通知报警方案,其实很好解决,抽象出去一个通知接口以及核心参数,并提供 SPI 加载方式,基本上就能完成开源兼容适配。
2. 依赖监控工具 Cat
美团线程池支持查看内部任务级别的执行情况,进行细粒度任务级别监控。
核心原理是通过 Cat Transaction 打点进行的支持,下图表就是从 Cat 上汇总进行展示。

Cat 这种依赖,不太好替换,因为会对原有业务代码进行侵入。如果说开源方案的话,可能就需要牺牲一部分功能性或者针对动态线程池框架底层实现这一功能。
3. 依赖消息队列 Kafka
通过美团文章中看到线程池框架使用了 Kafka 消息队列,这里暂且当一个存疑点,动态线程池中哪部分业务需要使用 Kafka 呢?
如果说使用动态线程池功能,还需要依赖消息队列,这可能对于大部分场景来说是说不通用的。

如果要进行开源,我的建议和想法是将这里设置为可替换项。也就是说默认不支持 MQ 功能,同时对市场上主流 MQ 进行适配。如果客户端项目想用的话,可根据项目实际选择。
比较常见的是 Seata 和 SkyWalking 的做法,以 SkyWalking 举例,链路数据存储支持 H2 、MySQL 、ElasticSearch 等数据库,让用户根据场景以及服务体量灵活选择。
4. 动态线程池是监控体系中的“小”模块
之前有和美团的一位技术朋友沟通过,为什么美团的动态线程池框架没有开源出来?
他给我的回复是,动态线程池框架只是美团监控体系下一个“小”模块。
而且,根据不可靠消息,似乎内部该框架的实现不止一个,如果有美团的哥们看到可以评论下。
5. 小结
经过上面的分析,在这里我得出一个结论:美团在最初设计开发动态线程池时,似乎就没有打算对外开源。因此才会依赖如此多的组件以及美团内部的产品。
上文中所有想法都是笔者主观想法,实际情况有待考究。
如何识别框架是否官方开源
1. 开源仓库
国内公司中开源框架比较多的,基本上都会在 GitHub 命名空间下运维项目。
这里列举一些大厂开源公司对应的官方 GitHub 地址。
- 阿里巴巴: https://github.com/alibaba
- 腾讯: https://github.com/tencent
- 美团: https://github.com/meituan
- ......
2. 依赖包地址
在我们导入依赖包的时候,会输入 groupId 、artifactId 、version 三种信息,是否官方开源在 groupId 上基本就能体现出来。
groupId:一般由三部分组成,标识.公司名.项目名,拿 Apache 、Alibaba 两个组织的 groupId 举例子说明。
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>${shardingsphere-jdbc-core-spring-boot-starter.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
<version>${spring-cloud-starter-alibaba-nacos-discovery.version}</version>
</dependency>
所以,如果说项目为官方开源,那么通过 groupId 很容易就能辨别出来。
3. 非官方地址就不是官方开源的么
非官方地址就不是官方开源的么,也不一定,并不是所有项目都在公司命名空间下发展。
有些项目是独立于公司创建的命名空间,比如说阿里的 seata 、ant-design 等。
再比如美团一篇比较火的文章,讲的是操作日志如何记录,相信大多数同学也都有看到。
GitHub: https://github.com/mouzt/mzt-biz-log
同样不是官方开源,但是开源项目是由文章本人进行维护,代码质量和项目活跃度不输官方维护项目。
什么是 Hippo4j
上面说了很多关于开源的小知识,接下来向大家介绍下笔者开源的动态线程池框架 Hippo4j 。
原理:通过对 JDK 线程池的增强,以及扩展三方框架底层线程池等功能,为业务系统提高线上运行保障能力。
Hippo4j 提供了两种模式,一种是 依赖配置中心,另一种是 无中间件依赖,部署个 Jar 包就能带来 Web 端控制台使用。
GitHub: https://github.com/opengoofy/hippo4j
Gitee: https://gitee.com/magestack/hippo4j
1. 线程池痛点
如果有在项目中实际使用线程池,相信你可能会遇到以下痛点:
- 线程池随便定义,线程资源过多,造成服务器高负载。
- 线程池参数不易评估,随着业务的并发提升,业务面临出现故障的风险。
- 线程池任务执行时间超过平均执行周期,开发人员无法感知。
- 线程池任务堆积,触发拒绝策略,影响既有业务正常运行。
- 当业务出现超时、熔断等问题时,因为没有监控,无法确定是不是线程池引起。
- 原生线程池不支持运行时变量的传递,比如 MDC 上下文遇到线程池就 GG 。
- 无法执行优雅关闭,当项目关闭时,大量正在运行的线程池任务被丢弃。
- 线程池运行中,任务执行停止,怀疑发生死锁或执行耗时操作,但是无从下手。
2. 功能支持
基于以上痛点,Hippo4j 提供以下线程池功能扩展支持:
- 全局管控 - 管理应用线程池实例。
- 动态变更 - 应用运行时动态变更线程池参数,包括但不限于:核心、最大线程数、阻塞队列容量、拒绝策略等。
- 通知报警 - 内置四种报警通知策略,线程池活跃度、容量水位、拒绝策略以及任务执行时间超长。
- 数据采集 - 支持多种方式采集线程池数据,包括但不限于:日志、内置采集、Prometheus 、InfluxDB 、ElasticSearch 等。
- 运行监控 - 实时查看线程池运行时数据,自定义时间内线程池运行数据图表展示。
- 功能扩展 - 支持线程池任务传递上下文;项目关闭时,支持等待线程池在指定时间内完成任务。
- 多种模式 - 内置两种使用模式:依赖配置中心 和 无中间件依赖。
- 容器管理 - Tomcat 、Jetty 、Undertow 容器线程池运行时查看和线程数变更。
- 框架适配 - Dubbo 、Hystrix 、RabbitMQ 、RocketMQ 等消费线程池运行时数据查看和线程数变更。
- 变更审核 - 提供多种用户角色,普通用户变更线程池参数需要 Admin 用户审核方可生效。
- 动态化插件 - 内置多种线程池插件,支持用户自定义插件以及运行时扩展。
- 多版本适配 - 经过实际测试,已支持客户端 SpringBoot 1.5.x => 2.7.5 版本(更高版本未测试)。
3. 小结
截止目前,共计 30+ 公司 线上使用 Hippo4j 管理应用线程池,使用公司中包括支付、电商、快递、保险以及教育等行业。
同时,共有 86 名 开源同学对 Hippo4j 进行了代码贡献,有 10 名 小伙伴持续投入较多精力维护,晋升为 Hippo4j Committer ,得到官方支持 Jetbrains 全家桶 Licenses 。
最后总结
关于动态线程池的热度一直居高不下,本篇文章讲述了美团动态线程池的上下文,以及对为什么没有开源进行了简单分析。
最终得出的结论是:美团最初设计动态线程池时就没有打算开源,所以才会依赖美团相关中间件以及 Kafka 等“重量级”组件。
同时针对有些同学说无法分辨框架是否官方开源,笔者针对这个话题做了几项总结输出。
最后,介绍了下 GitHub 开源领域中比较火的项目 Hippo4j ,如果各位同学觉得不错可以持续关注。
 |
1
koujyungenn 2023-02-17 08:22:01 +08:00 via Android
协程被广泛使用后,动态线程池是否会失去优势
|
 |
2
fackVL 2023-02-17 08:27:20 +08:00 via iPhone
别的不说,文字写得真好
|
 |
3
nomagick 2023-02-17 08:29:52 +08:00 via Android 我觉得你这个叫任务队列更合适,叫线程池属于碰瓷
|
 |
4
machen OP @koujyungenn 可能会吧,但这个需要时间来适应
|
 |
6
chendy 2023-02-17 09:08:53 +08:00 是不是应该去到推广节点…
|
 |
7
julyclyde 2023-02-17 09:13:26 +08:00 所以我有几个问题:
1 马称是谁? 2 你和美团的关系是怎样的? 3 有合适的身份来代表美团宣布“并没有……框架”这件事吗? 4 最后介绍自己的作品才是核心吧,何必搞美团来当引文呢,直接发到 /promotion 节点不就得了? |
 |
8
vishun 2023-02-17 09:14:03 +08:00
印象中以为是美团开源的,然后又在本站搜了下,发现不单单是你这个产品,还有另一个相同功能的产品`DynamicTp`,它在推广时标题是:[美团动态线程池开源框架 DynamicTp]( https://www.v2ex.com/t/903527),可能是受到这个影响的。
|
 |
11
liub34177 2023-02-17 09:23:02 +08:00
快成日经贴了,能不呢来点有创意的开源项目
|
 |
12
dqzcwxb 2023-02-17 09:24:51 +08:00
@koujyungenn #1 virtual thread 底层是 forkjoinpool,而 virtual thread 官方是不推荐池化的因为没有必要
|
 |
13
rapperx2 2023-02-17 09:29:21 +08:00 产品不错,但是没必要搞的花里胡哨的用美团来引文,会让人反感(都把我们当傻子呗,全都不知道你是来推广的)。
|
 |
14
Xusually 2023-02-17 09:35:28 +08:00
|
 |
15
vvickey 2023-02-17 10:15:42 +08:00
和谐和谐
|
 |
16
ufan0 2023-02-17 10:22:19 +08:00
曾经在站内看过一些文章,自己在项目中尝试用过,确实不错,因为我们此前有这些技术实现,替换后效果良好。
也看了一些实现,部分思想、设计以及细节确实令我感到惊讶,努力学习中。 另外,楼主站内资料的 github 地址应该更新了。 |
 |
17
cloudzhou 2023-02-17 10:22:21 +08:00
你这个需求,是为了动态修改线程池状态,但是这个反而不是我们更需要的,
我做了类似的一个线程池框架,最终实现是: --------------------------------------------------- # Executor 基于命名空间的公用线程池 ## 背景 - 合理使用 Java 线程池并没有想象那么容易,容易滥用 - 能否合理做到 try{}catch{},log ,reject(CallerRunsPolicy/AbortPolicy/DiscardPolicy) - 在尽量使用资源和防止滥用取得一个平衡 ## 设计 - 全局共用线程池,便于管理全部线程,唯一是要注意资源隔离 - 提供梯度降级线程池处理,最大并发控制 - wait group ( fork -> join 模型) - 监控上报(以 namespace 作为划分) - 优先级 - 保持和 java.util.concurrent.Executor 一致接口 ## 使用场景 ### 1. 需要限制最大并发线程数量 比如:kafka 消费,要防止积累的数据瞬间占用大量线程,必要时异步转同步,阻塞消费(典型场景:***) ``` executor.execute("process***", () -> { handle***(xxx); }, Opt.withMaxConcurrent(100)); ``` ### 2. 定义并发上限之后不同表现 ``` executor.execute("lowPriority", new Runnable(){...}, Opt.withRejectPolicy()); // CallerRunsPolicy 转变成为当前线程执行 // AbortPolicy 打印异常并且放弃 // DiscardPolicy 默默丢弃 ``` ### 3. 低优先级 比如: 可以丢失的异步任务,达到最大线程数之后,将放在低优先级 pool ( 64 线程) 执行,相互竞争 ``` executor.execute("lowPriority", new Runnable(){...}, Opt.withLowPriority()); ``` ### 4. fork -> join 模型 比如: 发出多个异步任务,等待集体完成 ``` executor.execute("job1", new Runnable(){...}, Opt.withConcurrentGroup("thread-group")); executor.execute("job2", new Runnable(){...}, Opt.withConcurrentGroup("thread-group")); executor.execute("job3", new Runnable(){...}, Opt.withConcurrentGroup("thread-group")); executor.wait("thread-group") // job 1-3 done ``` ### 5. log / monitor 对于开启的任务,都进行 log 和耗时监控,同时上报 monitor --------------------------------------------------- 搞一个全局线程池(最大可能是 2048/4096 ,...),通过同步原语控制并发数( or 百分比,10%) 来让资源最大化使用,但是同时不至于滥用资源,至于这个控制算法,需要仔细斟酌,这才是核心需要 至于那些资源动态改来改去,最多算是一个 1.0 版本,我们需要的是,让机器帮我们选择,作出决定。 |
 |
19
house600 2023-02-17 11:23:02 +08:00
像请教下 op ,DynamicTP 和你的产品有哪些区别
|
 |
20
byte10 2023-02-17 11:31:55 +08:00
协程会解决这个动态线程池的问题。 动态线程池实际上真的比较鸡肋,本身线程就有最大的线程数,粗略计算下就不会差太多,500 个跟 800 个的性能差距几乎没多少(如果是 500 个跟几千个,可能会有些明显)。如果差距很大,那么本质上该优化下游服务了,或者换一个语言去实现更好。
|
 |
21
mango111 2023-02-17 12:47:00 +08:00
大厂也没有几个项目在立项时就考虑开源,肯定都是基于业务需求孵化的,只有具备一定完成度了且有空+老板支持才会做开源,其实像耦合 cat ,耦合大象这些做下解耦肯定都不是阻塞的问题,无非就是项目组工作太忙没空搞开源 /项目核心换人了没人牵头了 /老板不挺觉得没产出这些原因
|
|
22
mango111 2023-02-17 12:48:01 +08:00
哦,2020 年出的啊,好像那段时间美团出了个开源项目撕逼的事儿,后来美团基本都不做开源了,嫌麻烦
|
 |
23
lmshl 2023-02-17 13:35:43 +08:00 时代变了,大人
   |


|
26
cloudzhou 2023-02-17 14:22:28 +08:00
@lmshl
这个倒是说得太早,尤其是 Java 世界,要原生支持协程且有一段时间。 即便支持协程,对于协程数量的控制还是要需要的,比如有时候消费延后的 kafka ,积累了几十万数据,任何语言启动几十万协程,都不是一个小代价,会系统抖动,影响其他逻辑。 只是技术上我一直倾向一个观点,不要依赖人,依赖算法,而这个 lib 只是提供了一个依赖人去修改的功能,就很鸡肋。 |
 |
27
fkdog 2023-02-17 14:34:33 +08:00 全局管控
动态变更 通知报警 数据采集 运行监控 功能扩展 多种模式 容器管理 框架适配 变更审核 动态化插件 多版本适配 ================ 说是动态线程池,动态修改参数的核心部分就那么几个类。 剩下的都是这些监控、配置、通知一类通用化的解决方案,可以整合到任意一个开源项目里。 隔一段时间就要看到这个 Hippo4j 出来做推广。 可以说是毫无新意。 国产开源项目就没几个能看到有新意的东西,都是些车轱辘倒来倒去。 我下次也可以搞一个动态 Hashmap ,扩容、树化的时候给钉钉微信推送一下消息,然后接进普罗米修斯监控。一个大而全的 HashMap 就出来了,我准备给这个项目起名为 HappyMap 。喜欢大家来 fork 。 |
 |
28
ztxcccc 2023-02-17 14:38:32 +08:00
可是美团真的好卡啊
|
 |
29
TWorldIsNButThis 2023-02-17 14:49:35 +08:00
@cloudzhou 这还是代码具体怎么写的问题吧,你向线程池提交几十万个 task 不也一样有问题
|

|
31
cloudzhou 2023-02-17 15:22:50 +08:00
@TWorldIsNButThis 是啊,我只是针对上面一个发言,就是协程不是万能的,并发控制一样需要,甚至因为协程更加容易滥用
|
|
32
dqzcwxb 2023-02-17 15:35:19 +08:00
@cloudzhou #26 别说几十万,哪怕是几十亿的 virtual thread 实际使用的线程也只有 cpu 核心数的数量(代码在 jdk19 java.lang.VirtualThread#createDefaultScheduler)
硬要说影响性能那就是这几十亿的对象把内存撑炸了,但是这跟 virtual thread 有什么关系呢? |

|
34
cloudzhou 2023-02-17 16:26:32 +08:00
@dqzcwxb 你说的都是 *理论上*,好像我们现实中没遇到这场景一样,还是 Go 的服务,够原生协程了吧
现实就是:几十万的协程,就把服务快击垮了,cpu 99% 以上,响应不过来,总有其他短板阿 你要是写一个 hello world ,确实可以不用考虑 |
 |
35
lesismal 2023-02-17 16:52:21 +08:00
|
 |
36
cubecube 2023-02-17 17:16:16 +08:00
@cloudzhou 你说的问题,根本不是线程池&&vt 层面能解决的了。单机计算能力绝对不足,用啥都没用。是架构的问题了。有虚拟线程,的确不需要啥动态线程池了,毫无必要。虚拟线程的资源消耗就和一个 Object 一个数量级,有啥可考虑的。
|
|
38
cloudzhou 2023-02-17 17:39:10 +08:00
@lesismal 我知道,你实现了一个 nio ,替代标准库,不过我的观点不在此,我的意思是,真实的业务,在这个网络层面之前,其他已经挂了,还没到这里,问题终究就是需要对资源进行限制
@cubecube 是,我赞成协程不需要池化和复用,只需要控制顶层资源 @house600 这里是这样做的: executor.execute("processNamespace", () -> handle***(xxx), Opt.withMaxConcurrent(100)); 的时候,把 runner 包装一下,执行方法前 processNamespace +1 ,之后 processNamespace -1 , 通过一个阻塞的变量控制: https://docs.oracle.com/javase/7/docs/api/java/util/concurrent/locks/Condition.html 计数器控制: https://stackoverflow.com/questions/69760046/java-conditions-with-locks 比如你设置了最多 10 线程,那么当前 10 线程可以,再 +1 = 11 的时候,就会触发等待,需要计数器 -1 才可以继续 |
|
39
cloudzhou 2023-02-17 17:47:59 +08:00
@house600 细节上,做了多个线程池的梯度下降处理,举个例子,定义线程池 poo1 -> pool2 -> pool3 ,最大线程数量从高往低,每个 namespace 定义的最大 pool 占用百分比,分别是 5%,20%,30%,类似这样,一个 namespace 最大占用线程数:
max = poo1*5% + pool2*20% + pool3*30% 除非同时有 20 个 namespace 都占用了那么 5%(那你系统一定有大问题),否则资源最大化同时,又有隔离限制,达到一个平衡 |
|
40
cloudzhou 2023-02-17 17:52:20 +08:00
|
 |
41
realpg 2023-02-17 18:43:17 +08:00
真会蹭
|
 |
42
LaurelHarmon 2023-02-17 18:46:47 +08:00 via Android
美团技术团队的博客写的不错
|

|
44
lesismal 2023-02-17 21:49:17 +08:00
> @lesismal 我知道,你实现了一个 nio ,替代标准库,不过我的观点不在此,我的意思是,真实的业务,在这个网络层面之前,其他已经挂了,还没到这里,问题终究就是需要对资源进行限制
@cloudzhou 看这个描述,你应该是不知道。。。 nbio 的资源都是可控的,比如协程数量:标准库 net.Conn 方案是每个连接一个协程,所以才会有你前面描述的几十万协程崩了的问题。nbio 里的协程池数量完全是可配置的,比如你百万个连接,不需要每个 Conn 一个协程,少量 io 协程(数量可配置)处理 io ,逻辑协程池(数量可配置、也可以用户定制自己的协程池实现)处理具体的请求。所以比如这百万个连接,并发度只有 1w ,那么同时存在的逻辑协程数量最多也就 1w 。 nbio 的 4 层、HTTP/Websocket 的资源都是可配置的,所以是可控的,只要你不想 OOM ,做合理的配置,就能做到自然均衡限流。 |
|
45
cloudzhou 2023-02-17 22:50:04 +08:00 @lesismal 你这逻辑,无非是,net.Conn 都会挂住一个协程,比如 Read 操作,到几百万协程
而你自己写了类似 epoll 监听,只有 readable connection 才会实际占据协程,对不? 我说的几十万协程,是指实际进行同步 io 的行为,比如消费 kafka 然后 db/redis/rpc 操作等,瞬间击垮对方 /自己系统 对于因为监听 io 阻塞的协程,其实 Go 官方也是足够用的,虽然看起来协程多很多 说点打击你积极性的话,我非常反感一些很底层操作,使用非官方库的行为,其中包括协程、nio 部分 真正有你这种需求的,只有有限的 im 、网络转发才需要 the key point: 绝大部分遇到的问题,都是 io 相关,说的天花乱坠,db/redis/log 先要看能不能抗住 很多人做的事情,很像是,把一个长板,构建的更长,然后给大家看,哇,我做了多厉害的工作,然后短板依在。 |
|
46
lesismal 2023-02-17 23:38:40 +08:00
@cloudzhou #45
戾气有点重啊,上来就一顿同行相轻,像是吃了火药,没必要。我相信你不是出于恶意,只是对自己技术比较自信,所以觉得别人说的没用。我以前也这样,所以能理解。 > @lesismal 你这逻辑,无非是,net.Conn 都会挂住一个协程,比如 Read 操作,到几百万协程 而你自己写了类似 epoll 监听,只有 readable connection 才会实际占据协程,对不? 差不多是你说的这个意思,传统的其他语言主流高性能的异步 io 部分,也都是如此,非阻塞 io ,可读时占用协程也是短暂占用,所以 io 线程 /协程数量不需要太多。 > 我说的几十万协程,是指实际进行同步 io 的行为,比如消费 kafka 然后 db/redis/rpc 操作等,瞬间击垮对方 /自己系统 对于因为监听 io 阻塞的协程,其实 Go 官方也是足够用的,虽然看起来协程多很多 你前面没有明确说你的几十万协程问题是自家业务这种类似消费 kafka 占用几十万协程,通常遇到的是每个连接一个协程的问题,所以我先入为主了以为是连接数相关的协程爆炸的问题。 但有一个点是相同的,我说的 nbio 之上的逻辑协程池是可控的,配合非阻塞 io ,是可以把这种协程数量爆炸的问题解决的。 比如你们业务阻塞消费 kafka 这种,是因为 topic 太多?是不是可以考虑下改进?比如很多数据 topic 发布到公共的 topic partition ,然后消费者数量就不用那么多,实际的 topic 作为消息的结构体字段,消费者再去自行分流处理。 db/redis/rpc 这些同样的,你们同时几十万个协程去怼下游本身的行为就是不好的呀。要想让自己的服务资源消耗与性能平衡,纵向分层的实现中,每层自己做好限流、连接池协程池这些限制,而不是一股脑都怼下去。 至于标准库一个连接至少一个协程的方案,你这里说够用,但是不代表别人家也够用啊,或者说成本不划算呀。流量大在线高的厂,硬件省 50-70%甚至更高,成本也是不小的。 > 说点打击你积极性的话,我非常反感一些很底层操作,使用非官方库的行为,其中包括协程、nio 部分 真正有你这种需求的,只有有限的 im 、网络转发才需要 the key point: 绝大部分遇到的问题,都是 io 相关,说的天花乱坠,db/redis/log 先要看能不能抗住 放心吧,你不会打击到我的,你自己都列出了几个有我这种需求的场景,而且别人实际业务也有需要的。另外啊,最常见的大厂 http 服务,用我这个替换标准库的话,本身就能省不少硬件、资源占用也可控。 你这些话我觉得有点自相矛盾了。 你前面提出的几十万协程问题,是指实际进行同步 io 的行为,后面楼层又说标准库的同步 io 也足够。足够为啥还造成了几十万协程然后扛不住了呢?那说到底不还是因为标准库同步 io 导致写成数量爆炸的问题吗?那到底标准库是足够不足够呢? > 很多人做的事情,很像是,把一个长板,构建的更长,然后给大家看,哇,我做了多厉害的工作,然后短板依在。 这是在说我做无用功吗?但是你确定你了解我的库吗? 举个例子,nbio 的 HTTP/Websocket 支持混合 io 模式,混合模式下,支持一定数量内的连接用标准库同步 io ,超过配置阈值的连接由 nbio 的 poller 进行异步 io ,这样的好处是,连接数阈值以内时,性能有保障,我简单压测了下,性能高于标准库、gorilla/websocket 。然后如果海量连接数进来时,照样资源占用可控、服务稳定。 |
|
47
lesismal 2023-02-17 23:47:08 +08:00
@cloudzhou
> 说点打击你积极性的话,我非常反感一些很底层操作,使用非官方库的行为,其中包括协程、nio 部分 但凡官方库好用够用消耗少能解决所有痛点,谁闲着蛋疼去重复造轮子啊。如果你是对的,那造轮子的人都是脑子有病似的,字节那帮搞这块地人都该被裁员才对得起资本家了 |
|
48
cloudzhou 2023-02-18 04:48:52 +08:00 @lesismal 我为我言语表示道歉,因为这个帖子本身在推广自己 lib (还蹭美团),你又贴了自己链接,导致把你也一顿输出~。不是相轻,相反,能写出这样项目的人,水平很高,因为需要知识扎实(我写不出来,除非我去看别人代码)。
> 你前面提出的几十万协程问题,是指实际进行同步 io 的行为,后面楼层又说标准库的同步 io 也足够。 回归这个问题,就是说不管是否池化,是否协程,对资源的限制都是需要的,否则下游都会击垮,因为真实环境,就是一定还会访问下游( db/redis/rpc )等 标准库的同步 io 也足够,是指如果只是挂在 net.Conn.Read() 的协程,那多一些也问题不大 --- 回到技术问题:之前没看你这个项目,这次去认真看了~ 但是,盲猜通过回调实现,比如 Java 里面的 netty ,只有这样才实现少数 io 协程分发 结果确实是: g.OnData(func(c *nbio.Conn, data []byte) { c.Write(append([]byte{}, data...)) }) 刚好我写过 netty 协议的 encoder/decoder ,还写过一些嵌入式类似回调解析协议 我的体验就是,回调式符合机器设计,不符合人类思想,维护状态是很累的 如果你用两种方式来解析 websocket 协议,就能体现明显差距 我说的“反感”,就类似,Golang 官方那么努力能你写平铺直叙的同步读写,一把给干回来了 我另外一个顾虑是:类似这种依赖某个 x 这么基础组件,有一天 Golang 升级到 xxx 版本了,协程更高效了 然后没有人敢升级,因为这个 x 组件重度依赖,做了好多高科技,没人敢动,这在我们技术上出现过 --- 说点我的技术选择: 1. 主流技术优先,Java 世界 Spring 一把梭,甚至按着官方文档来就好了; Golang 就官方库,在上面封装一下脚手架 2. 选择 /实现方案的时候:解决程序员心智问题优于其他,代码的可读性优于其他 --- 你这项目我准备 clone 下来看看怎么实现的 |
|
49
cloudzhou 2023-02-18 05:08:52 +08:00 @lesismal 我刚想说这种回调式写法,协议要使用状态机去实现,就看到你 nbhttp 用状态机解析 http 协议
omg ,这工作量我都不敢想,但是你确定实现了一个完整的 http 协议解析了吗?这工作量可不小 |
|
50
lesismal 2023-02-18 12:52:13 +08:00
@cloudzhou
> 因为这个帖子本身在推广自己 lib (还蹭美团),你又贴了自己链接,导致把你也一顿输出~。 没事的,我以前的一些工作面向的在线连接数比较大,加上有一些旧的技术惯性——服务端方案总是想考虑解决 10k/100k/1000k 的问题,go 这方面不太行所以自己有一些应对方案。看到你们也确实遇到协程爆炸的问题,所以想随便交流下。想推广的时候我就自己也单独发过推广贴了,之前发过,不过感觉 v 站相关的流量不大,所以就不怎么发了,推广随缘,能多多交流就好,哈哈哈 > 回到技术问题:之前没看你这个项目,这次去认真看了~ > 但是,盲猜通过回调实现,比如 Java 里面的 netty ,只有这样才实现少数 io 协程分发 > 结果确实是: > g.OnData(func(c *nbio.Conn, data []byte) { > c.Write(append([]byte{}, data...)) > }) 其实这里只是 4 层的,要想省协程解决网络相关的协程爆炸的问题,不能主动去阻塞读写,一阻塞就长时间占用协程,所以只能以回调的方式做,其他语言或者 go runtime 也都是这样。 > 刚好我写过 netty 协议的 encoder/decoder ,还写过一些嵌入式类似回调解析协议 > 我的体验就是,回调式符合机器设计,不符合人类思想,维护状态是很累的 因为 4 层 TCP/UDP 只是数据流 /数据报过来,并不能确保每次受到的数据就是 7 层应用协议的一个完整包,加之为了解决协程爆炸问题、用回调的方式收数据、不用阻塞读写,就只能自己维护状态机了。同样的,除了 golang/erlang ,其他语言的高性能异步非阻塞 io 也都是这样做,目前的计算机科学体系里,绕不过这种方案。 > 如果你用两种方式来解析 websocket 协议,就能体现明显差距 其实不是用两种方式来解析 websocket ,而是两种 io 收数据,然后传递给 websocket 解析器。 标准库那种同步解析器阻塞等待读到自己想要的数据量、没办法处理这种非阻塞 io 的 conn 每次不能保证读到它想要的数据就返回 err 的场景。 nbio 的 websocket 解析器只有一解析器,就是你上面说的状态机、异步流解析器。因为这种解析器不关心你单次传递的数据是不是完整包或者多个包,给数据过来就行了,所以它是大于同步解析器的、也能处理同步解析器的场景。 所以就不需要两种解析器,只需要支持多种数据来源就行。 nbio 支持不同的 io 模式是因为,以前的版本只有异步 io 这种,io 协程池读到数据解析出来需要传递给逻辑协程池。如果直接在 io 协程池中处理、当前 conn 处理完当前消息后才能进行其他 conn 的读取、其他 conn 就都慢了。而传递给逻辑协程,这就带来了更多的逃逸、协程切换的成本,buffer 、obj 的生命周期和 pool 优化也都比基于标准库的方案更复杂并且性能差一点。以标准库或者 fasthttp 为例,它们的读 buffer 和各种对象,是同一个协程中 for 循环处理,复用和 pool 优化都很容易,而且如果数据量不是特别大,这些还都是栈上变量,协程亲和性都要好得多。而 nbio 异步 io 这种传递给另外的逻辑协程池,在连接数不是特别大的场景,性能就要差一截了,在连接数阈值达到了的时候才能发挥优势。所以又加上了不同 io 模式的支持,高在线低在线的性能、占用、稳定性更加均衡了。 > 我说的“反感”,就类似,Golang 官方那么努力能你写平铺直叙的同步读写,一把给干回来了 4 层上没办法,原因如前面所述。 但是对于 7 层,其实异步流解析的部分是 nbhttp websocket 框架内做好了的。 你看一下 nbio 的 HTTP 和 Websocket 例子,在你的 HTTP Handler 或者 Websocket 的 OnMessage Handler 里,其实你仍然同平铺直叙的同步逻辑去写业务的。 比如 nbio 对 gin 、echo 的支持,多数业务的 gin 、echo 代码不用变、只要替换 nbio 作为网络层就可以了。 少量的性能场景比如想要 zero copy 的 sendfile 之类的,需要一些业务代码改变,刚好前阵子有人遇到过这问题,更让我没想到的是,gin 、echo 这些自己实现了 Response 竟然还不支持 zero copy ,详情再这里: https://github.com/lesismal/nbio/issues/263 再以 websocket 为例,比如使用 gorilla/websocket ,是需要自己处理 io 的,比如用一个协程循环读,如果业务涉及广播、还应该用另一个协程+chan 去处理写(否则单个 conn 写阻塞时,广播的 for 循环里其他 conn 就要等待了)。 但是如果用 nbio 的 websocket ,你不需要去自己处理 io 的部分了,只需要写业务逻辑就可以了。 > 我另外一个顾虑是:类似这种依赖某个 x 这么基础组件,有一天 Golang 升级到 xxx 版本了,协程更高效了 未来协程更高效是有可能的,但我估计主要是体现在创建回收复用和调度的效率上,但解决不了根本问题: 1. 因为 go 是有栈协程,所以只要同时存在大量协程,协程的资源占用问题应该是解决不了 2. 大量协程大量上下文变量,GC 的 CPU 消耗也是很难,uber 那些做了很多自己的优化,但仍然压力大 nbio 的方式是相当于把连接数对应的协程数量和上下文省掉了,只是处理当前,而且这个并发度是数量可配置的协程池,超过这个并发度的被协程池内存池资源自然限流等待就相对均衡了。比如协程池数量配置成 5w 这个级别,go runtime 调度和 GC 都不会有压力,业务层即使有阻塞操作,比如每个请求的处理时常 100ms ,1s 能处理 10 轮,5w*10 也能 50w qps/tps ,这数字只是举例子,多数业务比这小得多、应该是足够了。如果不够用,那就还是业务压力大于系统资源能力的问题,怎么都得加机器了。 配置更低的节点想用更少资源,协程池就再配置小点比如 1w 、甚至 1k ,用户自己定制就行 > 然后没有人敢升级,因为这个 x 组件重度依赖,做了好多高科技,没人敢动,这在我们技术上出现过 即使标准库也是有 bug ,所以这个只能是使用者以规范的工程流程做好业务的不同测试,还有就是对于多节点的服务,可以分步、一节点一节点或者一批次一批次地更新技术方案,技术升级把影响范围控制好,稳定的版本不轻易升级。 然后就是社区多互动打磨稳定性了。 > 你这项目我准备 clone 下来看看怎么实现的 欢迎欢迎,多多交流! > 我刚想说这种回调式写法,协议要使用状态机去实现,就看到你 nbhttp 用状态机解析 http 协议 omg ,这工作量我都不敢想,但是你确定实现了一个完整的 http 协议解析了吗?这工作量可不小 HTTP1.x 这个倒是不难,目前遇到过的最难的部分是 TLS 的异步流解析魔改,因为协议更复杂、版本和代码 if else 分支多、工作量大,所以选择了在标准库 TLS 上直接魔改,爆肝生病了好几次:joy:。 还有更难的一些,目前 nbio 的异步 io 部分只支持了 HTTP1.x ,2.0 、3.0/QUIC 都还没支持,工作量太大,不知道什么时候有档期去搞了。。。 |
 |
51
xmrvabc2 2023-02-18 13:40:44 +08:00 via Android
你这个东西能赚钱吗,还不是靠业务,年轻人不要老是想着学什么技术,多学学业务才是王道
|
|
56
cloudzhou 2023-02-22 19:08:41 +08:00
|